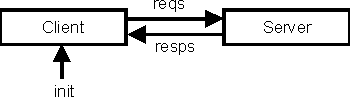
Una Introducción agradable a Haskell
anterior siguiente
inicio
Antes vimos varios ejemplos de comparación de patrones en definiciones de funciones- por ejemplo length y fringe. En esta sección revisaremos con detalle el proceso de comparación de patrones (§3.17). (La comparación de patrones de Haskell es diferente a la utilizada en los lenguajes de programación lógicos, como Prolog; en particular, en Haskell puede verse como una comparación "uni-direccional", mientras que en Prolog es "bi-direccional" (via la unificación), con vuelta-atrás implícita en el mecanismo de evaluación.)
Los patrones no son de "primera-categoría;" existe
un conjunto fijo de patrones diferentes. Vimos varios ejemplos
de patrones como los constructores de datos; las funciones
length y fringe anteriores usan tales patrones,
la primera usa constructores predefinidos (listas), y la segunda
patrones definidos por el usuario (Tree). Por tanto, al
comparar patrones se permiten constructores de cualquier tipo,
definidos por el usuario o no. Esto incluye tuplas, cadenas,
números, caracteres, etc. Por ejemplo, he aquí una función que concuerda tuplas de "constantes":
contrived :: ([a], Char, (Int, Float), String, Bool) -> Bool
contrived ([], 'b', (1, 2.0), "hi", True) = False
Este ejemplo ilustra que se permite el anidamiento de
patrones (de profundidades arbitrarias).
Técnicamente hablando, los parámetros formales (el Informe los llama variables.) son también patrones---para éstos nunca falla la comparación de patrones. Como "efecto lateral" de una comparación con éxito, la variable se instancia al valor comparado. Por esta razón, no se permite que una ecuación tenga variables repetidas como patrones. (propiedad que llamamos linealidad §3.17, §3.3,§4.4.3).
Patrones como las variables, que nunca fallan, se llaman irrefutables, en contraste con los patrones refutables que pueden fallar. El patrón usado en el ejemplo de la función contrived es refutable. Existen otros tres tipos de patrones irrefutables, dos de los cuales introducimos a continuación (el otro lo postergamos hasta la Sección 4.4).
Algunas veces es conveniente dar un nombre a un patrón para
poder usarlo en la parte derecha de una ecuación. Por ejemplo la
función que duplica el primer elemento de una lista podemos
escribirla así:
f (x:xs) = x:x:xs
(recordemos que ":" es asociativo a la
izquierda.) Nótese que x:xs aparece como patrón en la
parte izquierda y como expresión en la parte derecha. Para
mejorar la lectura, desearíamos escribir x:xs una sola
vez, lo cual se consigue utilizando un patrón-nombrado
como sigue: (Otra ventaja es relativa a la implementación ya que
en lugar de reconstruir completamente x:xs se usa el
valor comparado.)
f s@(x:xs) = x:s
Técnicamente hablando, un patrón-nombrado siempre tiene
éxito, aunque el patrón que nombre pueda fallar.
Otra situación corriente es comparar con un valor que
realmente no necesitamos. Por ejemplo, las funciones head
y tail definidas en la Seción 2.1 pueden reescribirse
como:
head (x:_) = x
tail (_:xs) = xs
en las cuales hemos "avisado" del hecho de que no
necesitamos cierta parte del argumento de entrada. Un comodín
puede "emparejarse" con un valor arbitrario, pero en
contraste con las variables, no se instancia a nada; por esta
razón, se permiten varios comodines en la misma ecuación.
Vimos cómo son comparados los patrones individuales, cómo algunos son refutables y cómo otros son irrefutables, etc. Pero, ¿cómo se activa el proceso global? ¿en qué orden se intentan las comparaciones? ¿qué ocurre si ninguna tiene éxito? En esta sección discutimos estas cuestiones.
La comparación de patrones puede fallar, puede tener éxito, o puede divergir. Una comparación exitosa instancia (liga) los parámetros formales del patrón. La divergencia ocurre cuando un valor necesario es evaluado a error (_|_). El proceso de comparación se produce "hacia-abajo y de izquierda a derecha". El fallo de un patrón en algún lugar de una ecuación produce un fallo de toda la ecuación, y entonces se intenta con la siguiente ecuación. Si todas las ecuaciones fallan, el valor de la aplicación de la función es _|_, y entonces se provoca un error en tiempo de ejecución.
Por ejemplo, si comparamos [1,2] con [0,bot], entonces 1 no encaja con 0, y el resultado en un fallo. (Notemos que bot, definido anteriormente, es una variable con valor _|_.) Pero si comparamos [1,2] con [bot,0], entonces la comparación de 1 con bot produce divergencia (i.e. _|_).
Una excepción a este conjunto de reglas es el caso en que los
patrones (globales) puedan tener una guarda booleana, como
en la siguiente definición de función que implementa una
versión abstracta de la función signo:
sign x | x > 0 = 1
| x == 0 = 0
| x < 0 = -1
Nótese que podemos proporcionar una secuencia de guardas
para el mismo patrón, y como cón éstos, las guardas son
evaluadas hacia abajo, y la primera que se evalue a True
produce un éxito en la comparación.
Las reglas de la comparación de patrones pueden tener efectos
delicados sobre el significado de las funciones. Por ejemplo,
consideremos la siguiente definición de take:
take 0 _ = []
take _ [] = []
take n (x:xs) = x : take (n-1) xs
y la siguiente versión ligeramente diferente (donde hemos
invertido el orden en las dos primeras ecuaciones):
take1 _ [] = []
take1 0 _ = []
take1 n (x:xs) = x : take1 (n-1) xs
Notemos entonces las siguientes reducciones:
| take 0 bot | => | [] |
| take1 0 bot | => | _|_ |
| take bot [] | => | _|_ |
| take1 bot [] | => | [] |
Vemos que take está "más definida" con respecto a su segundo argumento, mientras take1 está más definida con respecto a su primer argumento. Es difícil decir cual de las dos definiciones es mejor. Solo diremos que en ciertas aplicaciones podremos diferenciarlas. (El Standard Prelude incluye la definición correspondiente a take.)
La comparación de patrones proporciona una forma de "transferir el control" basada en las propiedades estructurales de un valor. Sin embargo, en varias situaciones no queremos definir una función para este fin, sino solamente especificar cómo realizar la comparación de patrones en la definición de funciones. Las expresiones case de Haskell proporcionan una forma para resolver este problema. En efecto; en el Informe se especifica el significado de la comparación de patrones a través de expresiones primitivas "case". En particular, una definición de función de la forma:
| f p11 ... p1k = e1 |
| ... |
| f pn1 ... pnk = en |
donde cada pij es un patrón, es equivalente semánticamente a:
f x1 x2 ... xk = case (x1, ..., xk) of
| (p11, ..., p1k) -> e1 |
| ... |
| (pn1, ..., pnk) -> en |
donde los xi son identificadores nuevos. (Una
traslación más general, que incluya construcciones con guardas,
puede verse en §4.4.3.)
Por ejemplo, la definición de take anterior es
equivalente a:
take m ys = case (m,ys) of
(0,_) -> []
(_,[]) -> []
(n,x:xs) -> x : take (n-1) xs
Un aspecto no apuntado anteriormente es que por cuestiones de corrección de tipos, los tipos de los miembros derechos de una expresión "case" deben ser iguales; más exactamente, éstos deben tener el mismo tipo principal.
Las reglas de la comparación de patrones para las expresiones "case" son las mismas que para las definiciones de funciones, de forma que realmente no aportamos nada nuevo, salvo la conveniencia que ofrecen las expresiones "case".
Por el contrario, existe un uso de las expresiones case con una sintaxis especial: las expresiones condicionales. En Haskell, las expresiones condicionales tienen la forma familiar:
if e1 then e2 else e3
que realmente es una forma abreviada de:
| case e1 of | True -> e2 |
| False -> e3 |
A partir de este convenio, queda claro que e1 debe ser de tipo Bool, mientras que e2 y e3 deben tener el mismo tipo principal (aunque arbitrario). En otras palabras, if_then_else_puede verse como una función de tipo Bool->a->a->a.
Existe otra clase de patrones permitidos en Haskell llamados patrones perezosos, y tienen la forma ~pat. Estos son irrefutables: la comparación de un valor v con ~pat siempre tiene éxito, independientemente de la expresión pat. Operacionalmente hablando, si, posteriormente, un identificador de pat es "utilizado" en la parte derecha de la ecuación, éste será instanciado con la subexpresión del valor si la comparación de patrones tiene éxito; en otro caso, se instanciará con el valor _|_.
Los patrones perezosos son útiles en contextos donde aparecen estructuras de datos infinitas definidas recursivamente. Por ejemplo, las listas infinitas (usualmente llamadas streams) permiten describir en forma elegante programas de simulación. Como ejemplo elemental, consideremos la simulación de la interacción entre un proceso servidor server y un proceso cliente client, donde client envía una secuencia de peticiones a server, y server contesta a cada petición con alguna forma de respuesta. Esta situación se muestra en la Figura 2, al igual que para el ejemplo de la sucesión de Fibonacci. (Nótese que client también tiene un mensaje inicial como argumento.)
Utilizando streams para representar la secuencia de mensajes,
el código Haskell correspondiente a éste diagrama es:
reqs = client init resps
resps = server reqs
Tales ecuaciones recursivas son una traducción directa del
diagrama.
Además podemos suponer que la estructura del servidor y del
cliente son de la forma siguiente:
client init (resp:resps) = init : client (next resp) resps
server (req:reqs) = process req : server reqs
donde suponemos que next es una función que, a
partir de una respuesta desde el servidor, determina la siguiente
petición, y process es una función que procesa una
petición del cliente, devolviendo la respuesta apropiada.
Desafortunadamente, este programa tiene un problema serio:
¡no produce ninguna salida! El problema es que client,
como es usada recursivamente en la inicialización de reqs
y resps, espera una comparación con la lista de
respuestas antes de enviar la primera petición. En otra
palabras, la comparación de patrones se realiza "demasiado
pronto." Una forma de resolver el problema es redefinir client
como sigue:
client init resps = init : client (next (head resps)) (tail resps)
A pesar de que funciona, esta solución no es tan expresiva
como la anterior. Una forma mejor de resolver el problema es a
través de un patrón perezoso:
client init ~(resp:resps) = init : client (next resp) resps
Puesto que los patrones perezosos son irrefutables, la
comparación tiene éxito de inmediato, permitiéndose que la
petición inicial sea "enviada," y a su vez permitiendo
que se genere la primera respuesta; de esta forma
"arrancamos" el motor, y la recursión hace el resto.
Un ejemplo de cómo actua este programa es el siguiente:
init = 0
next resp = resp
process req = req+1
en el cual vemos que:
take 10 reqs => [0,1,2,3,4,5,6,7,8,9]
Como otro ejemplo de uso de patrones perezosos, consideremos
la definición de Fibonacci dada anteriormente:
fib = 1 : 1 : [ a+b | (a,b) <- zip fib (tail fib) ]
Podemos intentar reescribirla usando un patrón nombrado:
fib@(1:tfib) = 1 : 1 : [ a+b | (a,b) <- zip fib tfib ]
Esta versión de fib tiene la (pequeña) ventaja de
que no usa tail a la derecha, puesto que aparece
disponible en una forma no "destructiva" en el miembro
de la izquierda a través del identificador tfib.
[Este tipo de ecuaciones se llama un enlace a través de patrones (pattern binding); éstas son aquellas ecuaciones donde la parte izquierda completa es un patrón; obsérvese que tanto fib como tfib aparecen ligados en el ámbito de la declaración.]
Ahora, utilizando el mismo razonamiento que antes, deberíamos concluir que este programa no genera ninguna salida. Sin embargo, cursiosamente funciona, y la razón es simple: en Haskell se supone que el enlace a través de patrones tiene un carácter ~ implícito delante, reflejando el comportamiento esperado, y evitando algunas situaciones anómalas que están fuera del alcance de este tutorial. De esta forma, vemos que los patrones perezosos juegan un papel importante en Haskell, y de forma implícita.
A menudo es deseable generar un ámbito dentro de una expresión, con el objetivo de crear ligaduras o definiciones locales no "vistas fuera"---es decir, alguna forma de "estructuración por bloques". Para ello tenemos dos formas en Haskell:
Las expresiones let de Haskell son útiles cuando se
requiere un conjunto de declaraciones locales. Un ejemplo simple
es el siguiente:
let y = a*b
f x = (x+y)/y
in f c + f d
El conjunto de definiciones creada por una expresión let
es mutuamente recursiva, y la comparación de patrones es
tratada en forma perezosa (es decir, tienen un ~ implícito).
La únicas declaraciones permitidas son declaraciones de tipos
de funciones, enlace de funciones, y enlace de
patrones.
A veces es conveniente establecer declaraciones locales en una
ecuación con varias con guardas, lo que podemos obtener a
través de una cláusula where:
f x y | y>z = ...
| y==z = ...
| y<z = ...
where z = x*x
Nótese que ésto no puede obtenerse con una expresión let,
la cual únicamente abarca a la expresión que contiene.
Solamente se permite una cláusula where en el nivel
externo de un grupo de ecuaciones o expresión case. Por otro
lado, las cláusulas where tienen las mismas propiedades
y restricciones sobre las ligaduras que las expresiones let.
Estas dos formas de declaraciones locales son muy similares, pero recordemos que una expresión let es una expresión, mientras que una cláusula where no ---forma parte de la sintaxis de la declaración de funciones y de expresiones case.
El lector puede preguntarse cómo es que los programas Haskell
evitan el uso de punto-coma o algún otro tipo de separador con
objeto de determinar el final de las ecuaciones, declaraciones,
etc. Por ejemplo, consideremos la expresión let de la
última sección:
let y = a*b
f x = (x+y)/y
in f c + f d
¿Cómo distingue el analizador entre el código anterior y
el siguiente:?
let y = a*b f
x = (x+y)/y
in f c + f d
La respuesta es que Haskell usa una sintaxis bi-dimensional
llamada layout que esencialmente presupone que las
declaraciones están "alineadas por columnas." En el
ejemplo primero, nótese que tanto y como f
comienzan en la misma columna. Las reglas aparecen con detalle en
el Informe (§2.5,§B.3), pero en la
práctica, el uso es intuitivo. Únicamente hay que recordar dos
detalles:
En primer lugar, el siguiente carácter que siga a una de las palabras reservadas where, let, o of, determina la columna de comienzo donde deben escribirse las declaraciones locales correspondientes a where, let o case (esta regla también es aplicable a la cláusula where cuando se use en declaraciones de clases e instancias, que veremos en la Sección 5). Por tanto, podemos comenzar las declaraciones en la misma línea, o en la línea siguiente a la palabra reservada, etc. (La palabra reservada do, que discutiremos más tarde, también usa esta regla).
En segundo lugar, debemos asegurarnos que la columna de comienzo aparece más a la derecha que la correspondiente a la declaración actual (en otro caso tendríamos ambigüedad). El "final" de una declaración se detecta cuando aparece algo a la izquierda de la columna de comienzo asociada. (Haskell presupone que los tabuladores cuentan como 8 espacios; este detalle debe tenerse en cuenta cuando usemos un editor con otro convenio.)
El "Layout" es realmente una forma abreviada de un
mecanismo de agrupamiento explícito que debemos mencionar
ya que puede ser útil en ciertas circunstancias. El ejemplo de
expresión let anterior es equivalente a:
let { y = a*b
; f x = (x+y)/y
}
in f c + f d
Nótese las llaves y punto-coma. Tal notación explícita es
útil si queremos colocar varias declaraciones en una sola
línea; por ejemplo, la siguiente expresión es válida:
let y = a*b; z = a/b
f x = (x+y)/z
in f c + f d
Otros ejemplos de uso del layout con delimitadores pueden
verse en §2.7.
El uso del layout reduce en gran medida el desorden sintáctico asociado con los grupos de declaraciones, mejorando la legibilidad. Es fácil de aprender y recomendamos su uso.
Una Introducción agradable a Haskell
anterior siguiente
inicio